Supervised Learning
Supervised learning, also known as supervised machine learning, is a subcategory of machine learning and artificial intelligence
 admin
admin

Introduction:
With the passage of time, human beings learn from their experience, and on the basis of that experience, they make a decision. In a manner similar to how machine learning works, using patterns and algorithms from prior records, a computer may learn and adapt. Your computer analyses and infers from earlier data without explicit directions, projecting future results based on the foundations of existing records.
What is machine learning?
Machine learning is a category of data investigation that automates the formation of diagnostic models. This is a system that can extract information from data, diagnose patterns, and draw conclusions with little to no social interposition. The system is able to learn and evolve without being explicitly coded thanks to the use of artificial intelligence.
What is supervised learning?
Artificial intelligence is created through supervised learning. In this method, a computer's algorithms are trained by feeding it data (that has been appropriately labeled) for a certain outcome. The data is trained until it is able to recognize patterns and determine the link between the input data and the output labels. We may use this to determine the exact yield for a given label.
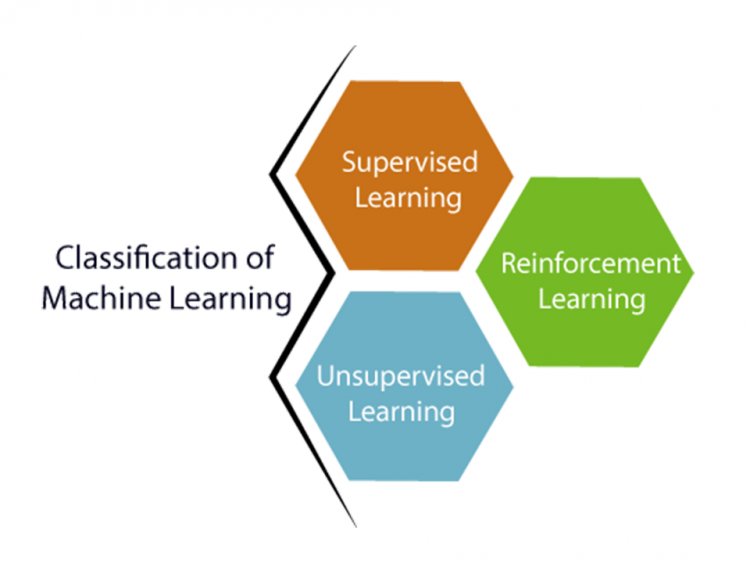
What are some examples of supervised learning?
In a nutshell, supervised learning is when we have an instructor train a machine using well-labeled data. By using the supervised learning method, the computer is given a new group or number of examples (data) to analyze the training data (set of training or preparation examples) and create an appropriate result from labeled data.
How does supervised learning work?
In supervised learning, we train the model by using a labeled data set. The model is trained according to each type of data. When the training process is completed, we test the trained model with the test data. On the basis of the previous training, the machine predicts the output.
Assume we have a dataset with a diversity of forms of triangles, such as squares, rectangles, and polygons. The classical must currently be trained for each shape as an initial phase.
- If a certain shape has four ends or corners and everything of them is equal, it is devoted to a square.
- The complete procedure will be labeled as a triangle if it has three sides.
- When a the entered shape has six equal sides, it is devoted to a hexagon.
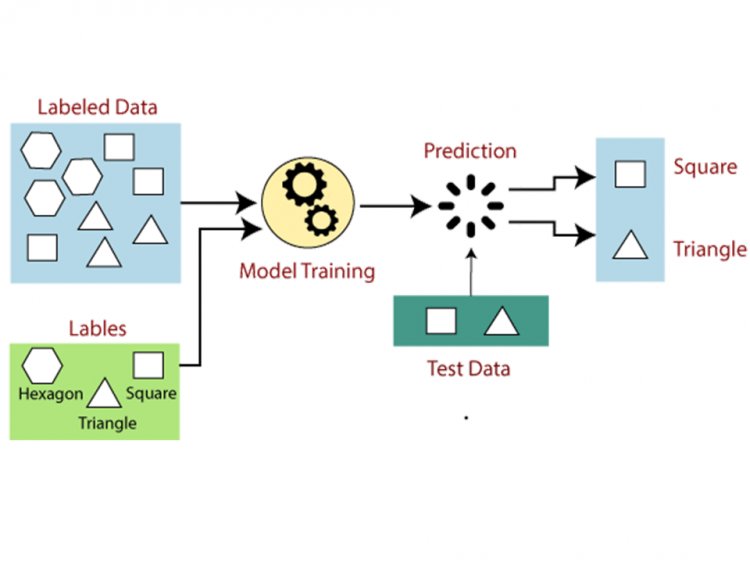
After training, we use the test set to put our perfect to the test, and the model's objective is to recognize the form.
The system has previously been taught in a variety of forms, and when it discovers a new one, it categorizes it.[1]
What steps are involved in machine learning?
- First, determine the type of training dataset you'll be using.
- Obtain the tagged training data by collecting and gathering it.
- Divide the training dataset into three parts: training, testing, and validation.
- Determine the training dataset's input characteristics, which should include enough information for the model to successfully predict the output.
- Choose an appropriate algorithm for the model, such as a support vector machine or a decision tree.
- Practice the training dataset to run the algorithm. Validation sets, which are a subset of training datasets, are occasionally required as regulators or control parameters.
- By giving the test set, you may assess the model's correctness. If the model correctly predicts the outcome, then our model is accurate.
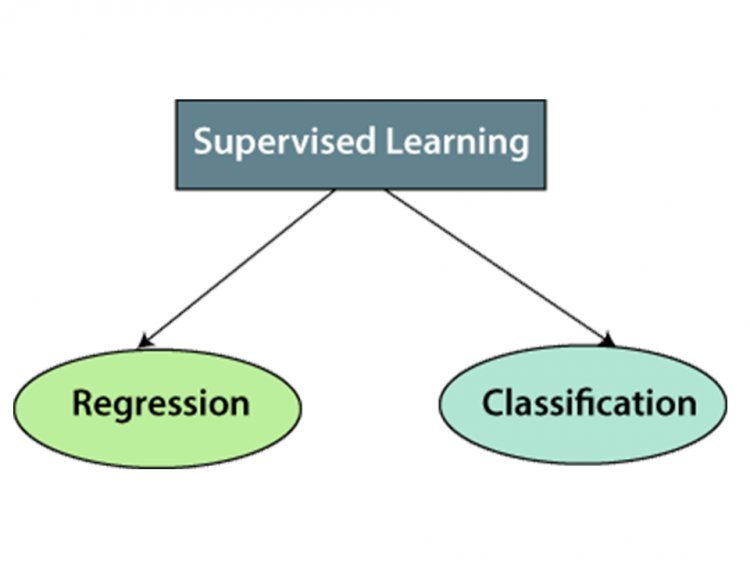
What are the categories of supervised learning?
The following are the categories that supervised learning has.
- Regression
- Classification
What are the Pros of supervised learning?
- In the teaching data, you will have a detailed opinion of the periods.
- You should be capable to understand how supervised learning mechanism. When it originates to unsupervised learning, we don't continually distinguish what's working on within the machine, how it's learning, and so on.
- Before succumbing to the data for exercise, you can regulate the detailed number of classes.
- You may be actually exact about the meaning of the classes, that is, you can train the classifier in such a method that it has a faultless decision borderline and can dependably discriminate among distinct classes.
- You don't require maintaining the teaching data in your memorial once you've concluded the full programmer. In its place, you may use a mathematical formula to retain the decision boundaries.[2]
What are the cons of supervised learning?
- In a diversity of ways, supervised learning is unnatural, and it cannot achieve some of the more problematical tasks in machine learning.
- Supervised learning, unlike unsupervised learning, cannot extract unidentified information from training data.
- Dissimilar unsupervised learning; cannot constellate or categorize data by determining its characteristics on its own.
- When it originates to classification, if we transport an input that is not from any of the classes in the training data, the result might be an improper class label. Let's imagine you used data from cats and dogs to train an image classifier. If you supply a giraffe image, the outcome may be either a cat or a dog, which is incorrect.
- Let's suppose your education set is missing certain instances and you'd like to add in a lesson. Then, following learning, you might not obtain the right class label as an input when you use those samples.
Conclusion:
Supervised learning excels in classification and regression issues, such as decisive the classification of the news article or forecasting the number of transactions for a future date. The goal of the supervised process is to learn the meaning of data in the context of a specific problem.
- Supervised Machine Learning. Available from: https://www.javatpoint.com/supervised-machine-learning.
- Petersson, D.supervised learning. Available from: https://www.techtarget.com/searchenterpriseai/definition/supervised-learning.